Yasunori Toshimitsu1,2,
Benedek Forrai1,
Barnabas Gavin Cangan1,
Ulrich Steger1,
Manuel Knecht1,
Stefan Weirich1,
Robert K. Katzschmann1
1: ETH Zurich 2: Max Planck ETH Center for Learning Systems


faive_gym tutorial video
This is a video tutorial on how to get started with the faive_gym library (which was developed in this paper) to train a policy with RL. It is a wrapper around IsaacGymEnvs supporting the Faive Hand. It is also straightforward to load other robot hand models in the same framework. Also see this blog post for how to create a MJCF model of your own robot and simulate it in IsaacGym.
Research Video
This is a 3-minute video showing the overview of this project.
Biomimetic Tendon-Driven "Faive Hand" with Rolling Contact Joints
At the Soft Robotics Lab, we have developed the Faive (pronounced "five") Hand, a biomimetic dexterous tendon-driven robotic platform for exploring dexterous manipulation. We aim to eventually provide a low-cost platform that makes dexterous manipulation research on real hardware accessible to many research institutes, accelerating the application of anthropomorphic robotic hands to real-life applications. For more about the Faive Hand project and Mimic Robotics (renamed from Faive Robotics), please visit mimicrobotics.com.
Rolling contact joint design
We use a prototype version of the Faive Hand with 11 actuatable degrees of freedom, with 3 in the thumb and 2 in each of the other fingers. Each finger contains a coupled joint at the distal end, and thus there are 16 joints in total. Similar to a human finger, our robotic finger design consists of three joints for which we apply a joint naming convention derived from human anatomy.
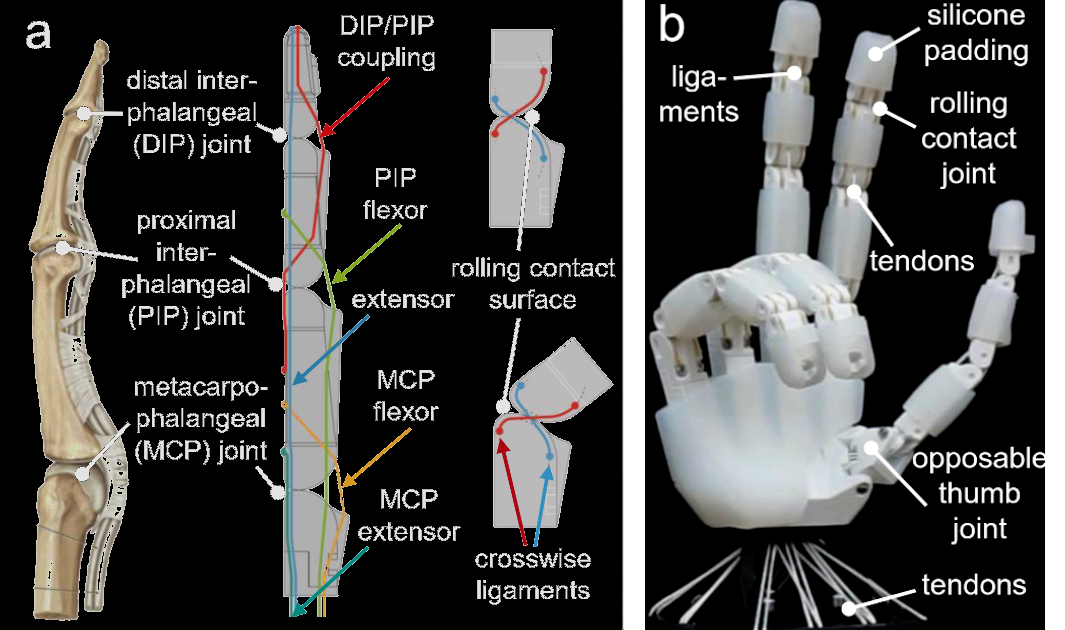
Apart from the carpometacarpal joint of the thumb which is recreated using 2 hinge joints, all of the
joints are implemented as rolling contact joints.
These rolling joints are composed of two articulating bodies with adjacent curved contact surfaces
connected by a pair of crosswise ligament strings.
These rolling contact joints do not have a single axis of rotation.
Thus they were modelled in simulation with two ”virtual” hinge joints.
The axes of these hinge joints were placed to go through the axis of the cylinder that constitutes each
rolling contact surface.
Demonstration of the rolling contact joint and the distal joint coupling on the real and simulated robot
The hand is tendon-driven by 16 Dynamixel servo motors within the wrist.
Low-level controller to enable joint control and sensing
The hand was simulated as a joint-driven robot, ignoring the tendon-level information. The tendon paths are geometrically modelled from the CAD data. We use an extended Kalman filter to estimate the joint angles from the tendon lengths.
Reinforcement Learning for Dexterous Manipulation
Trained policy visualized in IsaacGym.
Training the policy in a parallelized simulation environment
The policy is trained with RL with advantage actor-critic (A2C) using asymmetric observations (where different sets of observations are given to the actor and critic). 4096 robots are simulated in parallel on a single NVIDIA A10G GPU for about 1 hour to obtain the final policy.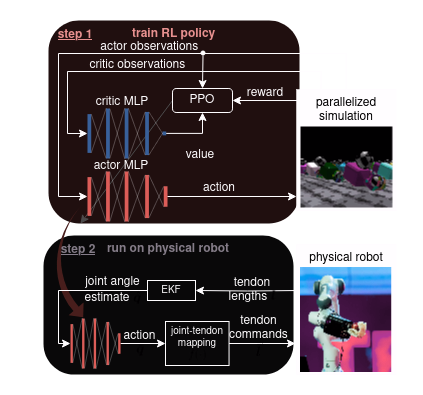
Overview of the RL training framework for achieving dexterous manipulation
on
the tendon-driven robot hand with rolling contact joints.

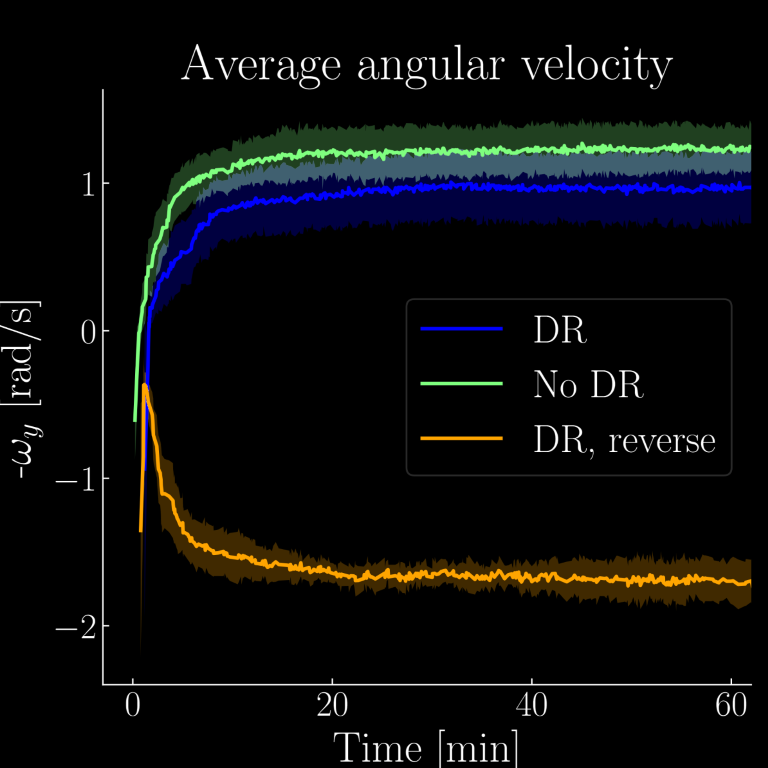
Training curve evolution for the policies, trained with and without domain randomization (DR / No DR), and for a reversed target rotation direction (reverse).
Running the policy on the real robot
We export the actor MLP to the real robot and run the closed-loop policy.
The performance difference across different random seeds was even larger when it was applied to the real
robot than it was within the simulation. Some policies even stopped moving the finger after a few seconds
of running the policy, getting stuck in a hand pose where the policy outputs zero values for actions.
Therefore, we ran each of the policies trained with separate random seeds, and picked the best performing
one from each condition to evaluate the bestcase performance for each.
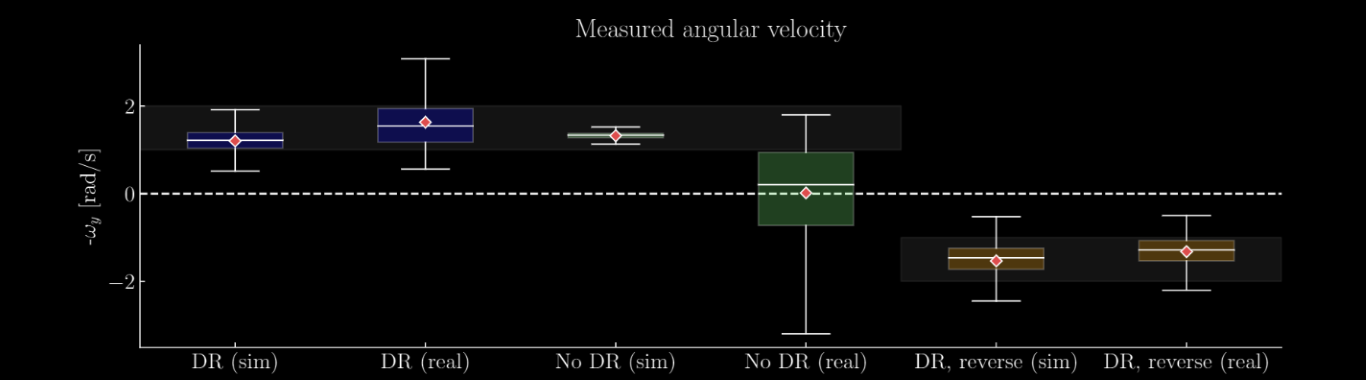
Distribution of the object rotational velocity on the real and simulated robot, for policies trained with and without DR. The gray strip indicates the region in which the object rotation reward is at its maximum value. The diamond indicates the mean.
The policies running on the real robot. The intended direction of rotation is indicated with an arrow.
When they are applied to the real robot, the importance of DR becomes apparent, as the non-DR policy fails to rotate the sphere, just rocking it back and forth in its hand. The DR policy succeeds in consistently rotating the ball, achieving the target rotational velocity for the majority of the measurements. The policy trained with a reversed rotational direction was also applied to the real robot, which again successfully rotated the ball to within the target velocity.
Acknowledgements
Yasunori Toshimitsu is partially funded by the Takenaka Scholarship Foundation, the Max Planck ETH Center for Learning Systems, and the Swiss Government Excellence Scholarship.
This work was partially funded by the Amazon Research Awards.
This work was also supported by an ETH RobotX research grant funded through the ETH Zurich Foundation.
Website template from yenchiah/project-website-template