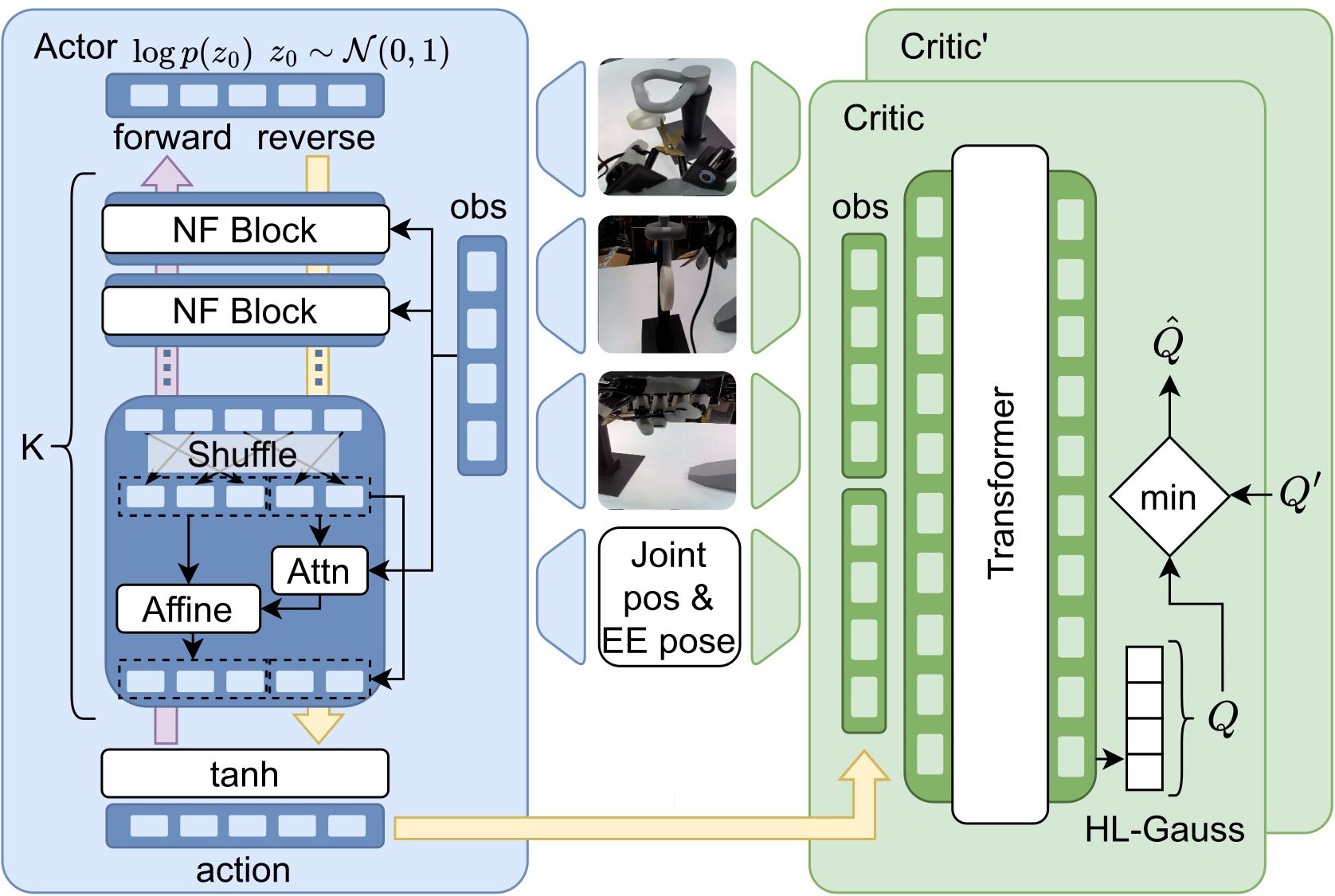
Normalizing-Flow Policy
Models action chunks with an invertible transformation conditioned on observations, enabling exact log-likelihoods and expressive multimodal behavior.
arXiv:2602.09580 (Feb 2026)
*Equal contribution; Soft Robotics Lab, D-MAVT, ETH Zurich
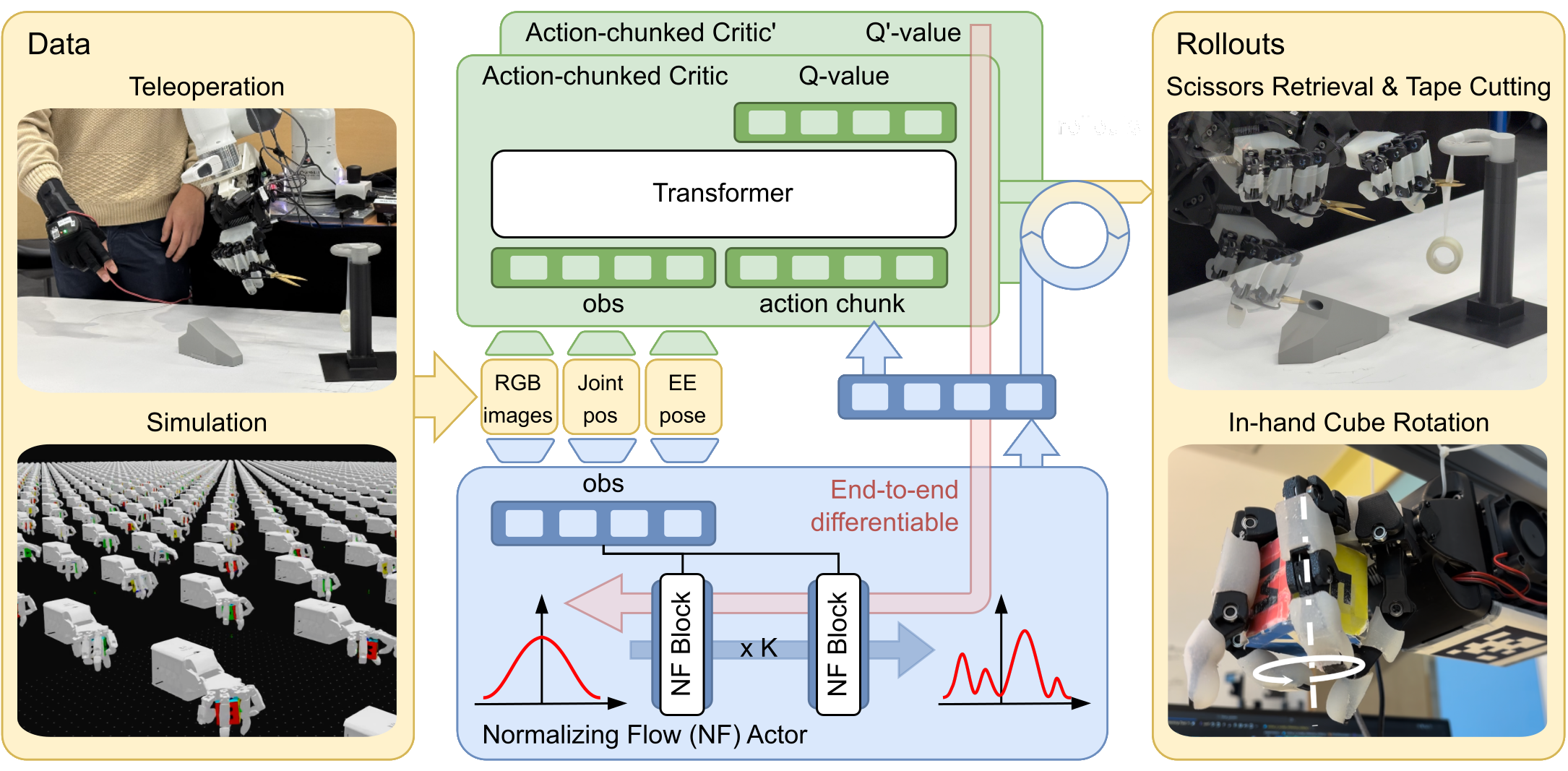
SERNF is a sample-efficient reinforcement learning algorithm based on normalizing-flow for dexterous manipulation. It combines a normalizing-flow policy (exact likelihoods for multimodal action chunks) with an action-chunked critic (value learning aligned with chunked execution). It enables stable offline-to-online adaptation on real robots under a limited interaction budget.
Real-world fine-tuning of dexterous manipulation policies remains challenging due to
limited real-world interaction budgets and highly multimodal action distributions.
Diffusion-based policies, while expressive, do not permit conservative likelihood-based
updates during fine-tuning because action probabilities are intractable. In contrast,
conventional Gaussian policies collapse under multimodality, particularly when actions
are executed in chunks, and standard per-step critics fail to align with chunked execution,
leading to poor credit assignment.
We present SERNF, a Sample-Efficient Reinforcement learning with Normalizing Flows to address these challenges. The normalizing-flow policy yields
exact likelihoods for multimodal action chunks, allowing conservative, stable policy updates
through likelihood regularization and thereby improving sample efficiency. An
action-chunked critic evaluates entire action sequences, aligning value estimation with
the policy’s temporal structure and improving long-horizon credit assignment.
We evaluate SERNF on two challenging real-world dexterous manipulation tasks:
scissors retrieval & tape cutting, and in-hand palm-done cube rotation.
On these tasks, SERNF achieves stable, sample-efficient adaptation.
Key idea: keep the policy expressive (multimodal action chunks) while making it tractable (exact log-likelihoods), and align value learning with the same temporal abstraction.
Models action chunks with an invertible transformation conditioned on observations, enabling exact log-likelihoods and expressive multimodal behavior.
Estimates value over entire chunks, matching the control interface and improving credit assignment under long horizons.
Starts from imitation learning (or sim-to-real distillation), then warm-starts the critic, runs offline RL, and finally performs online RL with a limited rollout budget.
marks successful rollout completion and failure.
Scissors retrieval & tape cutting — final after online RL.
In-hand palm-down cube rotation — final after online RL.
Duck pick-and-place — final after online RL.
Step 1: Imitation learning
Step 2: Offline RL
Step 3: Online RL
Step 1: Simulation teacher (PPO + domain randomization)
Step 2: Distilled policy (real)
Step 3: After critic warm-up
Step 4: After online RL
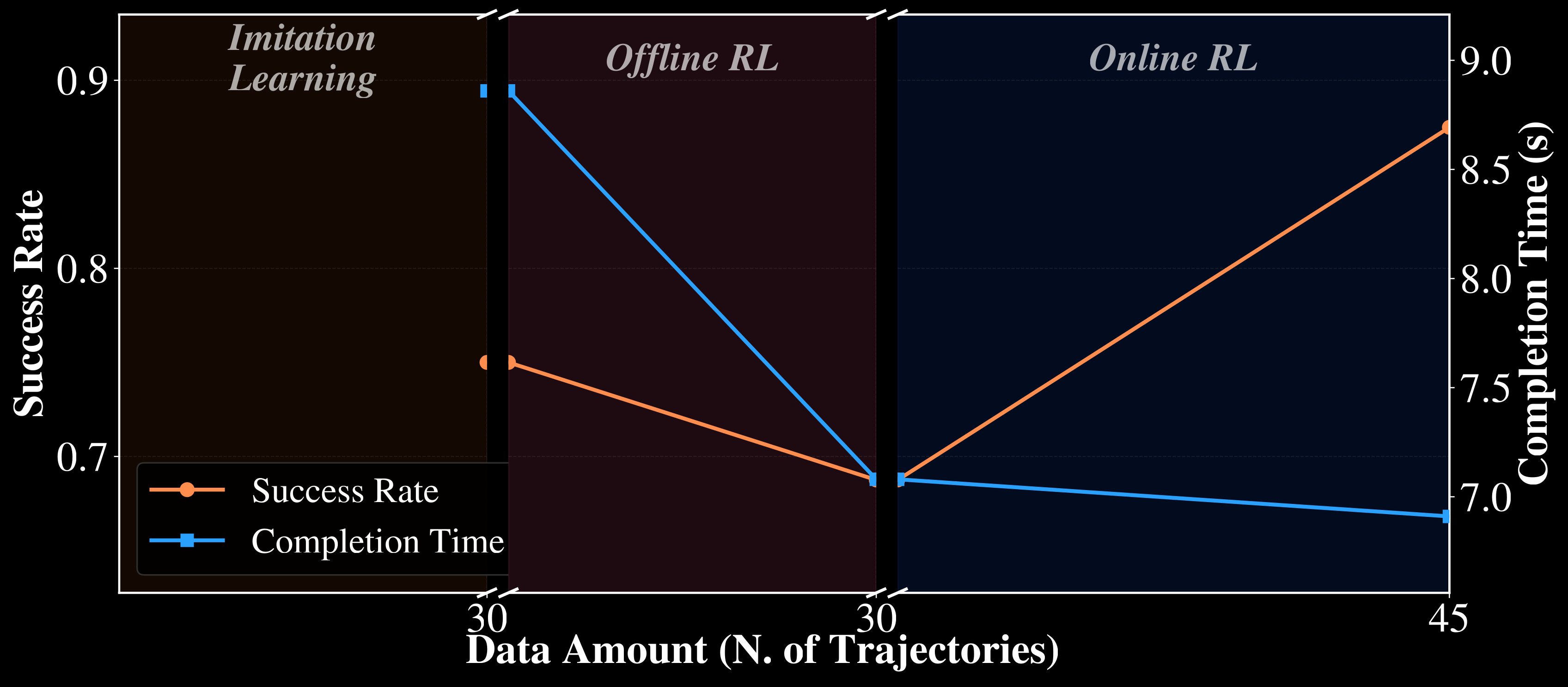
This task uses only 30 teleoperated demonstrations. The robot must pick the duck from varying table poses and place it into the bowl, making low-data adaptation substantially more challenging.
Step 1: Imitation learning
Step 2: Offline RL
Step 3: Online RL
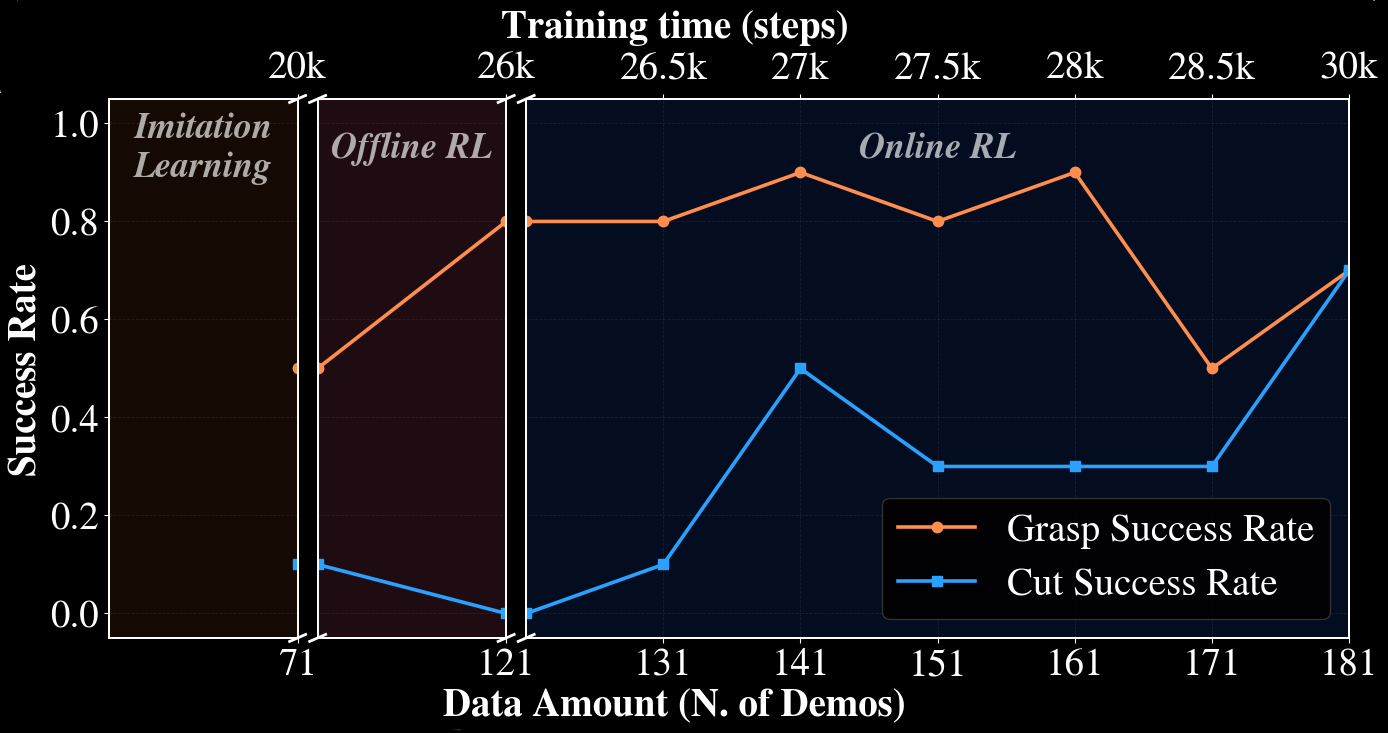
Starting from imitation learning, SERNF improves grasping with offline RL and enables successful cutting after limited online fine-tuning. In the paper’s summary table, SERNF reaches 70% grasp and 70% cutting success in the final setting.
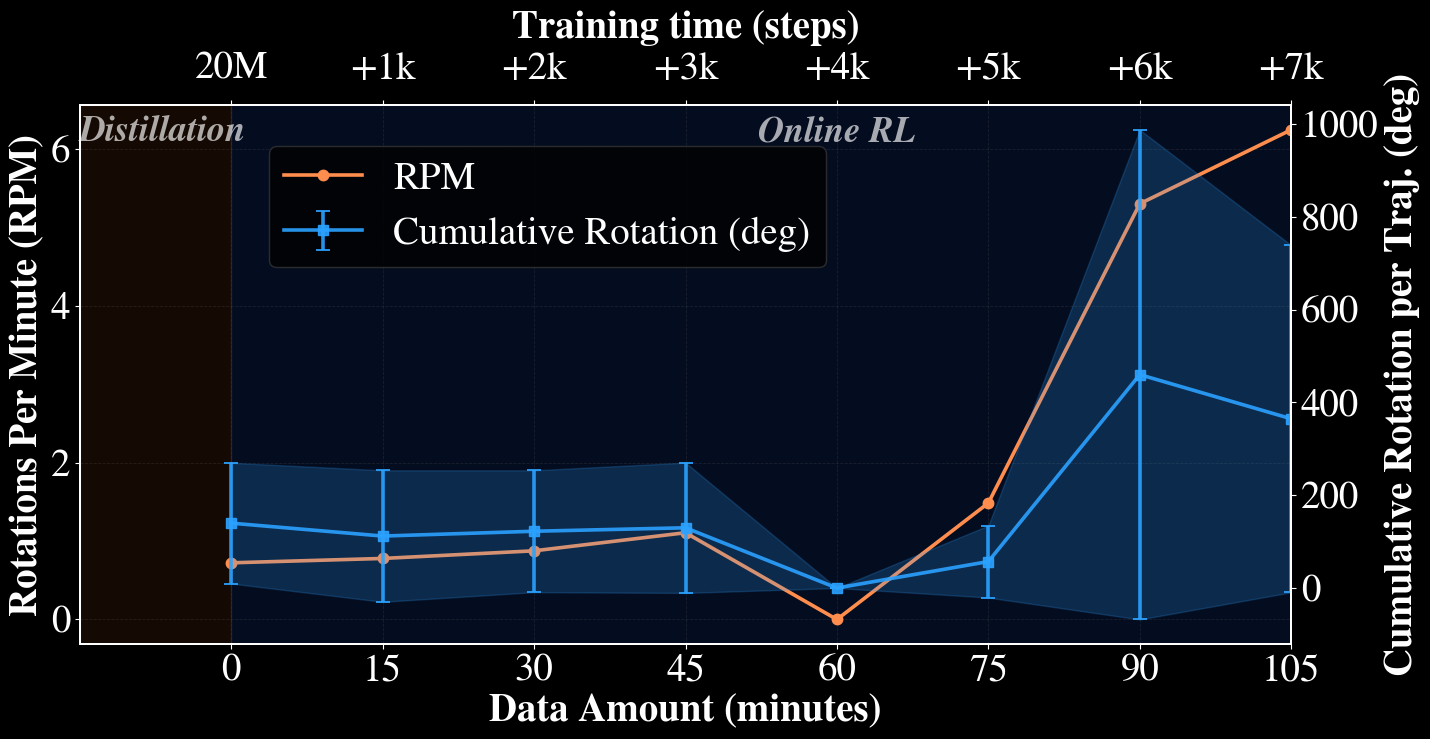
Online fine-tuning refines a distilled sim policy into robust real-world rotation. The reported peak performance reaches 6.25 rotations/min after about 105 minutes of real-world data.
With only 30 teleoperated demonstrations, the duck task is a challenging low-data setting. Even under varying pickup locations and orientations, offline RL reaches 68.75% success, and subsequent online RL with just 15 additional rollouts improves this to 87.5%, compared with 75% after imitation learning. On the subset of rollouts where all three policies succeed, RL also speeds up execution: average completion time drops from 8.86s for imitation learning to 7.08s after offline RL and 6.91s after online RL.
| Task | Stage | Summary |
|---|---|---|
| Scissors + tape | NF Imitation | 50% grasping, 10% cutting. |
| Scissors + tape | SOFT-FLOW (offline only) | 80% grasping, but cutting not yet solved. |
| Scissors + tape | SOFT-FLOW (full) | 70% grasping, 70% cutting after online RL. |
| Cube rotation | Distilled -> online RL | Performance grows to a peak of 6.25 rotations/min with stable continuous turns. |
| Duck pick-and-place | NF Imitation | 75% success with an average completion time of 8.86s. |
| Duck pick-and-place | SOFT-FLOW (offline only) | 68.75% success with an average completion time of 7.08s. |
| Duck pick-and-place | SOFT-FLOW (full) | 87.5% success after online RL with an average completion time of 6.91s. |
@article{yang2026sernf,
title={Sample-Efficient Real-World Dexterous Policy Fine-Tuning via Action-Chunked Critics and Normalizing Flows},
author={Yang, Chenyu and Tarasov, Denis and Liconti, Davide and Zheng, Hehui and Katzschmann, Robert K},
journal={arXiv e-prints},
pages={arXiv--2602},
year={2026}
}
}